




PyTorchによるCNNを用いた医療画像2クラス分類【EfficientNet】

今回の記事では、CNN(EfficientNet)を使って、画像分類をやってみたいと思います。
実装環境の準備(Google Colaboratory)
この記事では、Google Colaboratoryの環境を用いて実装していきます。
GPUが使えて、環境構築が簡単なため幅広く使用されています。
データセットの準備
今回使用するデータセットは、下記サイトから取ってきたものになります。
http://imgcom.jsrt.or.jp/minijsrtdb/
日本放射線技術学会 胸部X線画像の性別の2クラス分類データセット Gender01
こちらのデータセットは、胸部正面像が性別ごとに分けられており、どの性別かを予測する事に使用します。
▼ データセットはこちらの下記リンクからダウンロードしてください。
Google colaboratoryを前提に実装していきますが、ローカルのJupyter等の環境でも問題ありません。
ダウンロードが出来たらGoogleDriveにzipファイルのままアップロードしておいてください。
female:女性の胸部X線画像
male:男性の胸部X線画像
データセットの構造は、下図のようになっています。
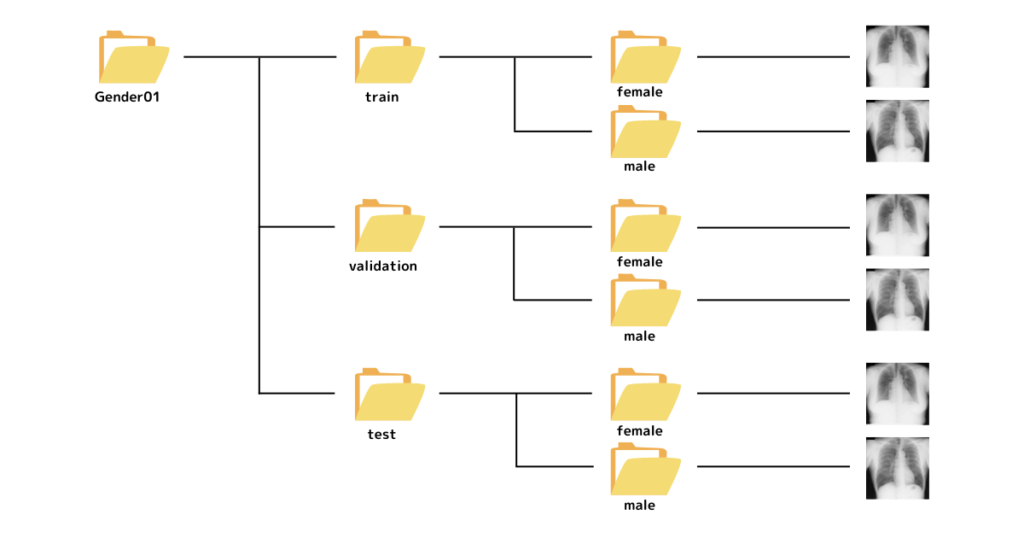
trainには学習用データセット、validationには検証用のデータセット、testにはテスト用データセットが含まれています。
一般的に、このようにtrain、validation、testの3つに分けておくと都合がよいです。
医療画像を用いたEfficientNetによる2クラス分類
それでは、これから実際にEfficientNetを使った学習を行うためのコードを書いていきます。
ライブラリのインポート
まずは自分のGoogleDriveにアップロードしたデータを使用するために、GoogleDriveと連携させる(Googleドライブのマウント)事を行います。
下記コードを実行する事で、Googleドライブのマウントは完了です。
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')続いて、先程アップロードしたzipファイルの解凍を行います。
解凍してからアップロードしてもいいですが、データ量が多い場合には時間がかかるので、zipファイルでアップロードして、コードで解凍する方がおすすめです。
from zipfile import ZipFile
# Zipファイルの解凍
file_name = '/content/drive/My Drive/Gender01.zip'
with ZipFile(file_name, 'r') as zip:
zip.extractall()次に、必要なライブラリをインポートしておきます。
from __future__ import print_function
import glob
import os
import random
import cv2
import time
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from PIL import Image
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
from torchvision.transforms import v2
from tqdm.notebook import tqdm
from pathlib import Path
import seaborn as sns
import timm
from pprint import pprint
from sklearn.metrics import confusion_matrix, accuracy_score, recall_score, precision_score, f1_score, roc_auc_score, roc_curve, auc
import matplotlib.pyplot as plt学習条件の設定をしていきます。条件を変更したい場合は、ここの数値を適宜変更してください。
# Training settings
epochs = 100
lr = 0.001学習用データセットの設定
cudaの設定と、データセットの保存してあるパスを指定します。
device = 'cuda'
train_dataset_dir = Path('/content/Gender01/train')
val_dataset_dir = Path('/content/Gender01/validation')
test_dataset_dir = Path('/content/Gender01/test')データセットの中身を確認します。
画像を表示してみて、データセットがうまく読み込めているか確認します。
files = glob.glob('/content/Gender01/*/*/*.png')
random_idx = np.random.randint(1, len(files), size=9)
fig, axes = plt.subplots(3, 3, figsize=(8, 6))
for idx, ax in enumerate(axes.ravel()):
img = Image.open(files[idx])
ax.imshow(img)
transformの設定
transformを使って、データセットの画像の前処理を行います。
train_transforms = transforms.Compose(
[
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
val_transforms = transforms.Compose(
[
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
test_transforms = transforms.Compose(
[
transforms.Resize(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]
)
・左右反転によるData Augmentation
・Tensor型へデータ変更
・正規化
データセットのロード
元のフォルダを読み込んで、データセット(画像とラベルのセット)を作成します。
train_data = datasets.ImageFolder(train_dataset_dir,train_transforms)
valid_data = datasets.ImageFolder(val_dataset_dir, val_transforms)
test_data = datasets.ImageFolder(test_dataset_dir, test_transforms)データをバッチに分けます。
今回は、batch_sizeを16にしていますが、GPUメモリが不足している場合は減らしましょう。
これで学習データセットのロードは完了です。
train_loader = DataLoader(dataset = train_data, batch_size=16, shuffle=True )
valid_loader = DataLoader(dataset = valid_data, batch_size=16, shuffle=False)
test_loader = DataLoader(dataset = test_data, batch_size=16, shuffle=False)EfficientNetのモデルをロード
timmを使ってEfficientNetのモデルをダウンロードし、さらに転移学習を実行していきます。
model_names = timm.list_models(pretrained=True)
pprint(model_names)コードを実行すると、上記のようにロードできるモデル一覧が表示されます。
今回は‘tf_efficientnetv2_s_in21ft1k’を使用します。
timmからpretrained modelをダウンロードします。
model = timm.create_model('tf_efficientnetv2_s_in21ft1k', pretrained=True, num_classes=2)
model = model.to(device)pretrain=Trueを指定することで、重みの学習が行われます。
num_classesは分類するクラス数をしていするので、今回は「female,male」の2クラスを指定します。
EfficientNetによる学習
損失関数、活性化関数の設定をします。
今回はクロスエントロピーとAdamを使用しますが自由に設定できます。
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)学習ループの設定、実行をしていきます。
また、最も良いモデルの重みの保存として、validationのlossが最も小さくなるような重みを保存します。
best_loss = None
# Accuracy計算用の関数
def calculate_accuracy(output, target):
output = (torch.sigmoid(output) >= 0.5)
target = (target == 1.0)
accuracy = torch.true_divide((target == output).sum(dim=0), output.size(0)).item()
return accuracy
train_acc_list = []
val_acc_list = []
train_loss_list = []
val_loss_list = []
for epoch in range(epochs):
epoch_loss = 0
epoch_accuracy = 0
for data, label in tqdm(train_loader):
data = data.to(device)
label = label.to(device)
output = model(data)
loss = criterion(output, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = (output.argmax(dim=1) == label).float().mean()
epoch_accuracy += acc / len(train_loader)
epoch_loss += loss / len(train_loader)
with torch.no_grad():
epoch_val_accuracy = 0
epoch_val_loss = 0
for data, label in valid_loader:
data = data.to(device)
label = label.to(device)
val_output = model(data)
val_loss = criterion(val_output, label)
acc = (val_output.argmax(dim=1) == label).float().mean()
epoch_val_accuracy += acc / len(valid_loader)
epoch_val_loss += val_loss / len(valid_loader)
print(
f"Epoch : {epoch+1} - loss : {epoch_loss:.4f} - acc: {epoch_accuracy:.4f} - val_loss : {epoch_val_loss:.4f} - val_acc: {epoch_val_accuracy:.4f}\n"
)
train_acc_list.append(epoch_accuracy)
val_acc_list.append(epoch_val_accuracy)
train_loss_list.append(epoch_loss)
val_loss_list.append(epoch_val_loss)
if (best_loss is None) or (best_loss > val_loss):
best_loss = val_loss
model_path = '/content/drive/MyDrive/bestViTmodel.pth'
torch.save(model.state_dict(), model_path)
print()
このような感じで学習が進んでいく様子が分かります。
学習結果の可視化
学習結果として、Accuracyとlossの曲線を出力していきます。
device2 = torch.device('cpu')
train_acc = []
train_loss = []
val_acc = []
val_loss = []
for i in range(epochs):
train_acc2 = train_acc_list[i].to(device2)
train_acc3 = train_acc2.clone().numpy()
train_acc.append(train_acc3)
train_loss2 = train_loss_list[i].to(device2)
train_loss3 = train_loss2.clone().detach().numpy()
train_loss.append(train_loss3)
val_acc2 = val_acc_list[i].to(device2)
val_acc3 = val_acc2.clone().numpy()
val_acc.append(val_acc3)
val_loss2 = val_loss_list[i].to(device2)
val_loss3 = val_loss2.clone().numpy()
val_loss.append(val_loss3)
#取得したデータをグラフ化する
sns.set()
num_epochs = epochs
fig = plt.subplots(figsize=(12, 4), dpi=80)
ax1 = plt.subplot(1,2,1)
ax1.plot(range(num_epochs), train_acc, c='b', label='train acc')
ax1.plot(range(num_epochs), val_acc, c='r', label='val acc')
ax1.set_xlabel('epoch', fontsize='12')
ax1.set_ylabel('accuracy', fontsize='12')
ax1.set_title('training and val acc', fontsize='14')
ax1.legend(fontsize='12')
ax2 = plt.subplot(1,2,2)
ax2.plot(range(num_epochs), train_loss, c='b', label='train loss')
ax2.plot(range(num_epochs), val_loss, c='r', label='val loss')
ax2.set_xlabel('epoch', fontsize='12')
ax2.set_ylabel('loss', fontsize='12')
ax2.set_title('training and val loss', fontsize='14')
ax2.legend(fontsize='12')
plt.show()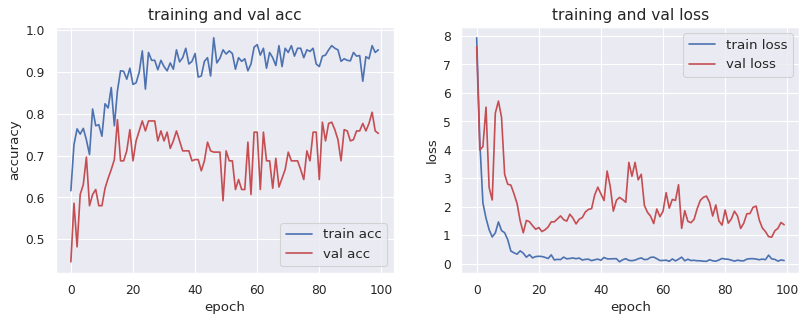
ここまでで、学習のステップは完了です。
テストデータによる検証
学習した結果を元に、保存したモデルの重みを用いて、テストデータで検証をします。
汎化性能の有無を検証します。
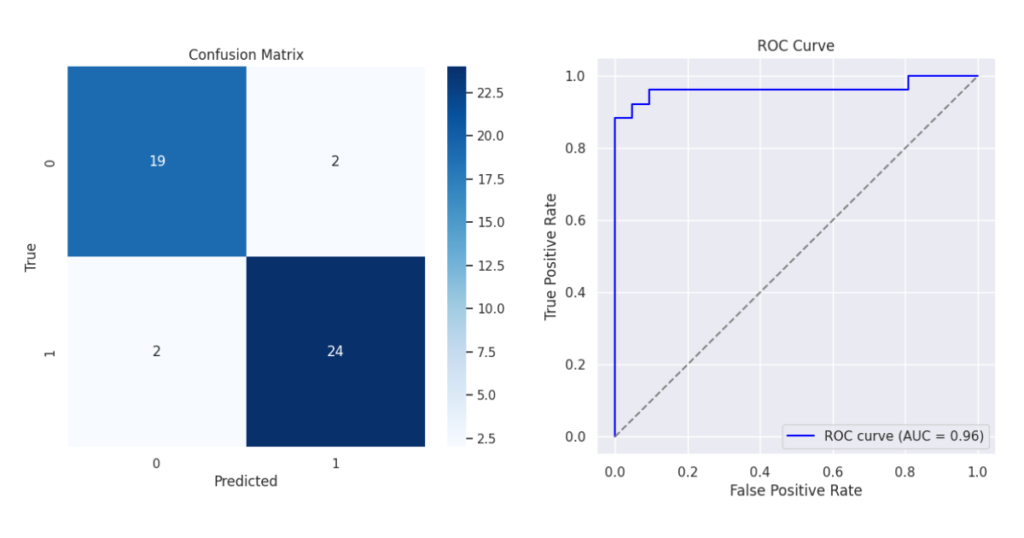
ROC曲線や各種評価指標により、評価を行います。
def evaluate_model(model, test_loader):
model.load_state_dict(torch.load("/content/drive/MyDrive/bestmodel_efficientnet.pth"))
model.eval()
predictions = []
actuals = []
probas = []
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
probas.extend(outputs[:, 1].cpu().numpy()) # 二番目のクラス(陽性クラス)の確率
predictions.extend(predicted.cpu().numpy())
actuals.extend(labels.cpu().numpy())
# 指標の計算
confusion = confusion_matrix(actuals, predictions)
accuracy = accuracy_score(actuals, predictions)
recall = recall_score(actuals, predictions) # 感度
specificity = recall_score(actuals, predictions, pos_label=0)
precision = precision_score(actuals, predictions) # PPV
npv = precision_score(actuals, predictions, pos_label=0) # NPV
f1 = f1_score(actuals, predictions)
auc = roc_auc_score(actuals, probas)
#print("混同行列:\n", confusion)
print(f"Accuracy: {accuracy:.4f}")
print(f"感度: {recall:.4f}")
print(f"特異度: {specificity:.4f}")
print(f"PPV: {precision:.4f}")
print(f"NPV: {npv:.4f}")
print(f"F-Score: {f1:.4f}")
print(f"AUC: {auc:.4f}")
# Confusion matrixの描画
# 混同行列の可視化
plt.figure(figsize=(7, 6))
sns.heatmap(confusion, annot=True, fmt="d", cmap="Blues")
plt.title("Confusion Matrix")
plt.ylabel("True")
plt.xlabel("Predicted")
plt.show()
# ROC曲線の描画
fpr, tpr, thresholds = roc_curve(actuals, probas)
plt.figure(figsize=(6,6))
plt.plot(fpr, tpr, color='blue', label='ROC curve (AUC = %0.2f)' % auc)
plt.plot([0, 1], [0, 1], color='gray', linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()
evaluate_model(model, test_loader)Accuracy: 0.9149
感度: 0.9231
特異度: 0.9048
PPV: 0.9231
NPV: 0.9048
F-Score: 0.9231
AUC: 0.9634
まとめ
今回の記事では、PyTorchによるCNNを用いた医療画像2クラス分類を実装してみました。
今回は、特に精度を上げるための工夫などはしていないので、ぜひDataAugmentationなどで精度が上がる方法を探してみてくださいね!
コメント