




pythonとkerasで医用画像分類【胸部X線画像の画像方向の4分類】

- Pythonとkerasを使って医用画像分類をしてみたい。
- Pythonによる医用画像分類の実践が知りたい。
- 実際にプログラミングに挑戦したい。
医療におけるプログラミングとして、pythonとkerasで医用画像分類する方法を解説します。
医療におけるAIを学び始めようとした初心者が「どうやってコードを書き換えたらいいの?」と最初の一歩で挫折してしまうケースは非常に多いです。
つまづく事なく医用画像分類が出来るようになってほしい。
そこでこの記事では、初心者でも出来る『pythonとkerasで医用画像分類』について解説します。
この記事を読めば「pythonとkerasで医用画像分類をする方法」の全てが分かります。
※こちらはあくまで研究用・練習用としてお使いください。
今回使用するデータセット
今回使用するデータセットは、下記サイトから取ってきたものになります。
日本放射線技術学会「標準ディジタル画像データベース[胸部腫瘤陰影像]」Direction01
http://imgcom.jsrt.or.jp/minijsrtdb/
こちらのデータセットは、胸部正面像が上下左右の4方向を向いた画像が含まれており、どの方向かを予測する事に使用します。
データセットはこちらの下記リンクからダウンロードしてください。
ソースコードはこちらの下記リンクからダウンロード出来ます。
環境
一応今回のソースコードの環境を載せておきます。
Google Colaboratory Windows11
誰でも環境構築無しで、実践するためにGoogle Colaboratoryを使用しています。
Google Colaboratoryの使い方などについては、こちらの記事で解説しています。
▼ Google Colaboratoryの使い方や準備についてまとめた記事はこちら

実際のコード
これから実際のコードを解説していきます。
上記で載せているノートブックをそのまま使用して頂いても構いませんが、実際に手を動かしてみる事が大事なので、ぜひチャレンジしてみてください!
前準備
まずは、コードを書いていく前に準備として先程ダウンロードして頂いたデータセットをzipファイルのままGoogle Driveにアップロードしておいてください。
そこまで出来たら実際にコードを書いていきます。
まずは自分のGoogleDriveにアップロードしたデータを使用するために、GoogleDriveと連携させる(Googleドライブのマウント)事を行います。
下記コードを実行する事で、Googleドライブのマウントは完了です。
# Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')マウントを行うと、こんな感じの表示が出ることがあります。
ログインするアカウントを選択してください。

そして、ログインするとこんな画面になるので、許可を押します。
するとマウントは完了になります。
データの確認
まずは、これから先使用するライブラリのインポートを行います。
Pythonにはそれぞれ便利な機能を持ったライブラリと呼ばれるものがあります。
インポートする事により、その機能を使用する事が出来ます。
# ライブラリのインポート
import numpy as np
import tensorflow.keras as keras
from keras.utils import np_utils
from keras.models import Sequential, Model, model_from_json
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
from PIL import Image
import glob
import json
from zipfile import ZipFile
%matplotlib inlineここで、先程アップロードしたzipファイルの解凍を行います。
解凍してからアップロードしてもいいですが、データ量が多い場合には時間がかかるので、zipファイルでアップロードして、コードで解凍する方がおすすめです。
# zipファイルの解凍
file_name = '/content/drive/My Drive/Directions.zip'
with ZipFile(file_name, 'r') as zip:
zip.extractall()実際に、正常に解答されているか、中身の画像を表示する事で確認を行います。
# 画像の表示
im = Image.open("/content/Directions/train/down/0.png", "r")
plt.imshow(np.array(im), cmap="gray")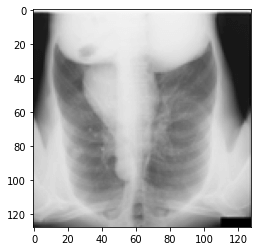
このように表示されていれば正常に動作しているのでOKです。
データの前処理
ここから実際に、データの前処理をしていきます。
ここでは、データセットに含まれている画像を配列に変換し、それぞれデータをXにラベルをyに格納します。
# データセットを変数に格納
# フォルダ名(分類クラス)のリスト
folder = ["down", "right", "left", "up"]
image_size = 32 #入力画像のサイズを32×32とする
#学習用データ、学習用ラベル、検証用データ、検証用ラベルをそれぞれ格納するための空の配列を作成
X_train = []
y_train = []
X_val = []
y_val = []
# 学習用(train)データに対して行う処理
for index, name in enumerate(folder):
dir = "/content/Directions/train/" + name #対象のフォルダ名
files = glob.glob(dir + "/*.png") #pngファイルのリストを取得
for i, file in enumerate(files):
image = Image.open(file) # 画像ファイルの読み込み
image = image.convert("RGB") # RGBモードに変換
image = image.resize((image_size, image_size)) # リサイズ
data = np.asarray(image) # 画像を配列に変換
X_train.append(data) # 配列をX_trainに追加
y_train.append(index) # ラベルをy_trainに追加
# 検証用(validation)データに対しても同じ作業を行う
for index, name in enumerate(folder):
dir = "/content/Directions/validation/" + name
files = glob.glob(dir + "/*.png")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_val.append(data)
y_val.append(index)
# numpy配列に変換
X_train = np.array(X_train)
y_train = np.array(y_train)
X_val = np.array(X_val)
y_val = np.array(y_val)
# 正規化
X_train = X_train.astype('float32')
X_train = X_train / 255.0
X_val = X_val.astype('float32')
X_val = X_val / 255.0
# 正解ラベルの形式を変換
y_train = np_utils.to_categorical(y_train, 4)
y_val = np_utils.to_categorical(y_val, 4)モデルの作成
ここでは、モデルの作成を行い、モデルを定義します。
# モデルの定義
def model(X, y):
model = Sequential()
model.add(Flatten())
model.add(Dense(64, activation='relu', input_shape=(256,)))
model.add(Dropout(0.2))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(4, activation='softmax'))
opt = keras.optimizers.SGD(lr=0.001, decay=1e-6)
model.compile(loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'])
return model学習を行うための準備
まずは、学習を行ったときの学習過程を可視化するように設定します。
学習過程における精度(accuracy)と誤差(loss)を可視化するように設定します。
# 学習過程を可視化
def plot_history(history):
plt.plot(history.history['accuracy'],"o-",label="accuracy")
plt.plot(history.history['val_accuracy'],"o-",label="val_acc")
plt.title('model accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.legend(loc="lower right")
plt.show()
plt.plot(history.history['loss'],"o-",label="loss",)
plt.plot(history.history['val_loss'],"o-",label="val_loss")
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(loc='lower right')
plt.show()ここでは、実際に学習を行う上で学習後テストを行う時に最も良いモデルで学習を行うために最良のモデルを保存しておくためのコードを書いておきます。
ここでは、誤差が最も小さくなるものを最良として定義し、最も小さくなるモデルを保存しておきます。
# 最良のモデルを保存するための関数
modelCheckpoint = ModelCheckpoint(filepath = 'direction_4.hdf5',
monitor='val_loss', # 監視する値
verbose=1, # 結果表示の有無
save_best_only=True,
save_weights_only=True,
mode='min',
)学習の実行
それでは、実際に学習を行います。
# 学習の実行
model = model(X_train, y_train)
history = model.fit(X_train, y_train,
epochs=50,
batch_size=32,
validation_data=(X_val, y_val),
callbacks=[modelCheckpoint])
json_string = model.to_json()
open('direction_4.json', 'w').write(json_string)
plot_history(history) 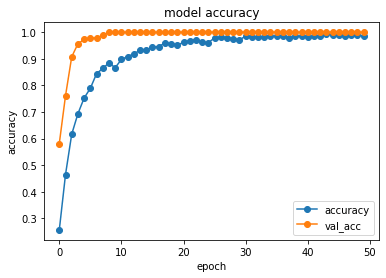
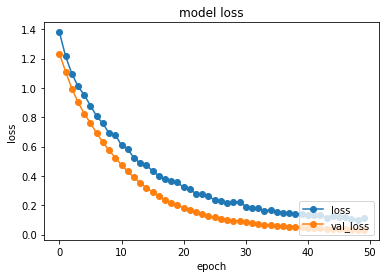
今回作成したモデルでは、かなりの高精度で学習が行えたことが分かると思います。
テスト用データでの検証
テスト用データで実際に正解できるかテストを行うために、まずはテスト用データの準備を行います。
まず、最良のモデルを読み込み、学習や検証用のデータセットと同様にテスト用データセットに対しても同じ処理を行います。
# テストの準備
# モデルを読み込む
with open('/content/direction_4.json', 'r') as model_json_file:
model_json = json.load(model_json_file)
model = model_from_json(json.dumps(model_json))
model.load_weights('/content/direction_4.hdf5')
X_test = []
y_test = []
for index, name in enumerate(folder):
dir = "/content/Directions/test/" + name
files = glob.glob(dir + "/*.png")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X_test.append(data)
y_test.append(index)
X_test = np.array(X_test)
y_test = np.array(y_test)
X_test = X_test.astype('float32')
X_test = X_test / 255.0
y_test = np_utils.to_categorical(y_test, 4)ここでテスト用データの準備は整いました。
しかし、その前にテストデータの画像と正解のラベルを表示してみたいと思います。
# 正解画像とラベルの表示
true_classes = np.argmax(y_test, axis = 1)
plt.figure(figsize = (16, 6))
for i in range(len(true_classes)):
plt.subplot(4, 15, i + 1)
plt.axis("off")
plt.title(folder[true_classes[i]])
plt.imshow(X_test[i])
plt.show()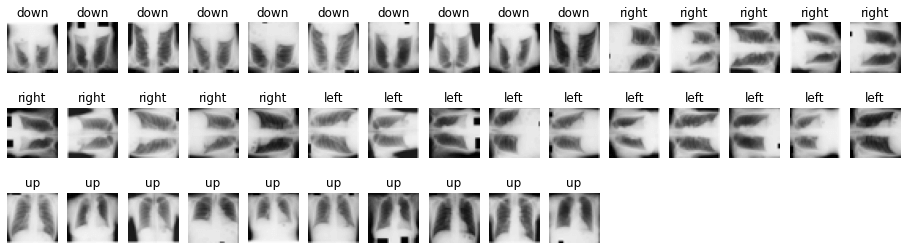
上記画像が正解画像とラベルのセットになります。
これと同じ結果を予測する事が出来れば、一番良いという事になります。
テストの実行
ここでは、いよいよテストの実行を行います。
# テストの実行
# testデータを予測する
pred = model.predict(X_test)
# 予測ラベル
pred_classes = np.argmax(pred, axis = 1)
# 予測確率
pred_probs = np.max(pred, axis = 1)
pred_probs = ['{:.4f}'.format(i) for i in pred_probs]
# testデータの画像と予測ラベル・予測確率を出力
plt.figure(figsize = (16, 6))
for i in range(len(pred_classes)):
plt.subplot(4, 15, i + 1)
plt.axis("off")
if pred_classes[i] == true_classes[i]:
plt.title(folder[pred_classes[i]]+'\n'+pred_probs[i])
else:
plt.title(folder[pred_classes[i]]+'\n'+pred_probs[i], color = "red") # 分類が間違っていた場合,赤字で書き込む
plt.imshow(X_test[i])
plt.show()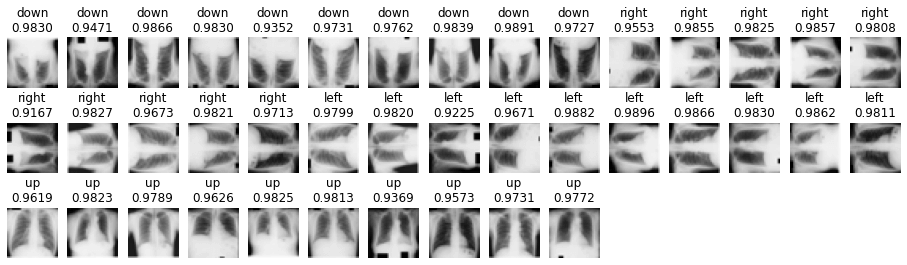
上記画像と数値が予測の結果になります。今回は、赤字での表示がないため全て正確に予測が出来たという事になります。
以上で、今回は終了となります。
まとめ
今回の記事では、pythonとkerasで医用画像分類【胸部X線画像の画像方向の4分類】を行う方法を解説しました。
ぜひ、参考にしていただけたら嬉しいです。
コメント