



機械学習とは?これだけは押さえておくべき知識【徹底解説】

- 機械学習を始めようと考えている人で機械学習について知りたい。
- 頑張りたい気持ちはあるけど、何からをつけていいか分かりません。
- まずは何から勉強したら良いか分からない…
機械学習において、知っておくべき基礎知識は数多くあります。
しかし、「何から学べばいいのか分からない。」と難しい本から始めて挫折してしまったりするケースは非常に多いです。
私は、これまで機械学習を勉強してきていろいろ遠回りをした事もありました。
効率よく基礎知識を学んでほしい。
そこでこの記事では、「機械学習において知っておくべき知識」について解説します。
それでは、さっそく見ていきましょう。
機械学習とは?

いきなりですが、皆様に1つ質問です。
「AIの定義を説明できますか?」
とは言え、いきなり言われても難しいですよね。でも、それでいいんです。実は、AIにはちゃんとした定義はありません。
強いてあげるとすれば、一般的には大量の知識データに対して、 高度な推論を的確に行うことを目指したもの(一般社団法人 人工知能学会設立趣意書からの抜粋)の様に説明されることがあります。
こんな風な記述のものが世の中にはとても多く感じます。
しかし、ただでさえ難しい分野を難しい言葉で書かれると読むのも疲れてしまいますよね。
これから簡単に分かりやすく説明していくので、よろしくお願いします。
機械学習の位置付け

上のような図を目にした事がある方も多いのではないでしょうか?
まずは、ざっくりと簡単に機械学習、そして最近よく聞くAIについてそれぞれがどのような位置付けにあるのかを見ていこうと思います。
機械学習の位置付けについてですが、一番広く、大きな枠組みが人工知能いわゆる「AI」になります。実は、最近よく聞くAIとはとても広い意味です。
その中に、機械学習や深層学習(ディープラーニング)と言ったものが含まれているという位置付けになります。
まずは、難しい中身は置いといてAIの中に機械学習やディープラーニングがあるんだなというくらいで覚えておいてくださいね。
機械学習とは
簡単に言うなら…
ある入力に対し、期待する出力を返してくれるような関数のパラメータを求めることだと言えます。
さらに詳しく説明すると、大量のデータからデータに潜むルールやパターンをプログラム自身が学習して発見し、そのルールやパターンを予測することであると言えます。
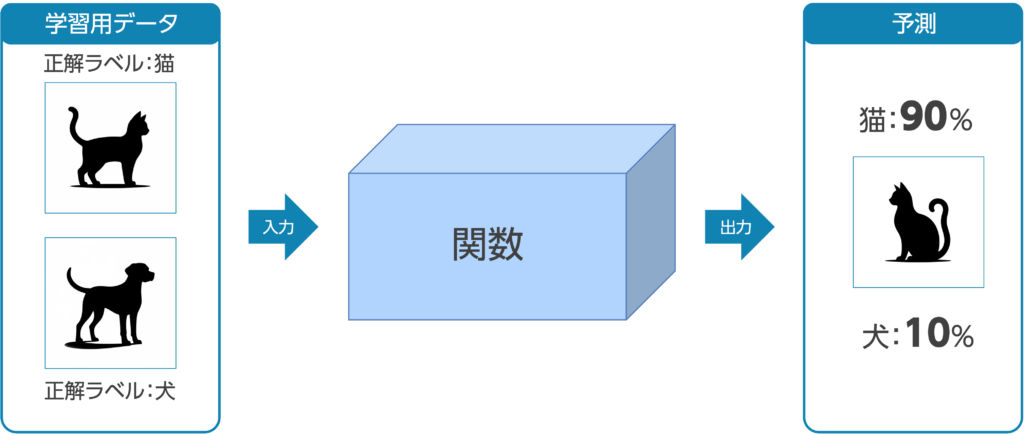
例として、犬と猫の画像を分類することを考えてみたいと思います。
上の図のように、犬・猫の画像を入力した時に、正しくイヌ・ネコという出力を返してくれるような関数を求めることであると言えます。
つまり!
機械学習を一言で説明するなら
データから自動で答えを導き出してくれるような関数を作らせること
であると言えます。
こんな風に考えたら、簡単ですよね。
さらには、自動で答えを導き出してくれるような関数をプログラム自身に学習させることが出来たらいろいろなことが出来そうで夢が広がりませんか?
機械学習ってすごいんだな!これが分かっていただけたらここまではOKです。
データセットの取り扱いについて

実際に、自分のオリジナルのデータで機械学習をやってみたい。そんな時に、気を付けておくべきこと、さらにこれだけは知っておいた方がいい事をこれからお話ししていきますね。
これから機械学習を勉強していく上でも、まずはこれらの知識から勉強していきましょう。
それではさっそく見ていきましょう。
データセットの取り扱いについて
まずはデータセットの取り扱いについて、例としてがんの良悪性鑑別のデータセット10万枚で考えていきたいと思います。
例.がんの良悪性鑑別モデル (10万枚の画像データセット)
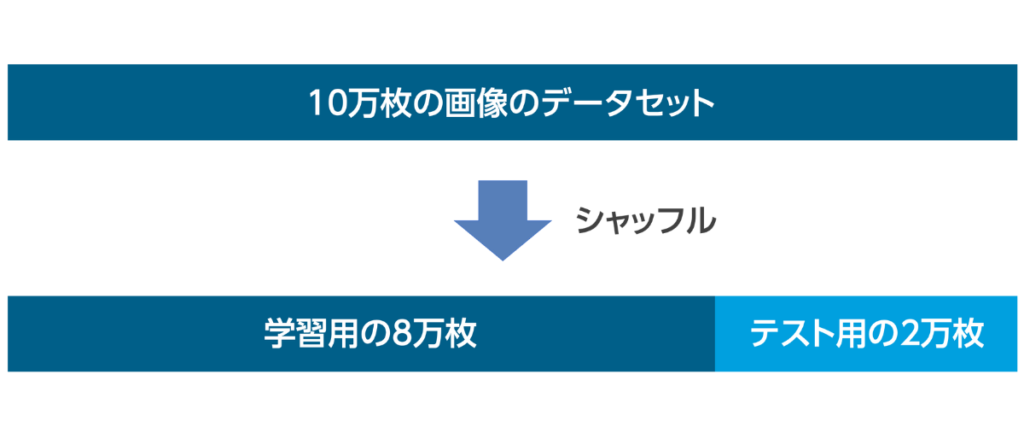
上の図のように元のデータセットを学習させる際には、訓練用のデータとテスト用のデータの2つに分割する必要があります。
当たり前な事ですが、重要なことなので覚えておく必要があります。

さらに大前提として、「モデルの学習には、テストデータについての情報を一切知らない」ことが望ましいとされています。
つまりは、モデルを作るためにデータセットを仮テストデータ(検証用:validation)、真のテストデータに分けるとさらに良いという事になります。
今回のデータセットの取り扱いの話については次の1文だけは覚えてください。
つまり、実際には訓練用、検証用、テスト用の3つにデータを分けるといい!という事になります。
データセットの分割についてはご理解いただけたでしょうか?
自分でモデルを作成する際に役立ててみてください。
leakage(情報漏洩)について

データを扱う上では、Leakage(情報漏洩)については最も重要と言っても過言ではありません。
あまり聞きなれない言葉かもしれませんが、情報漏洩についての知識がないとせっかくの研究や成果が全く意味のないものになってしまう場合もあるので気を付けましょう。
それでは、内容を見ていきましょう。
Leakage(情報漏洩)について
先程、大前提として、「モデルの学習には、テストデータについての情報を一切知らない」ことが望ましいと説明しましたが、どういう事なのか説明していきますね。
一言で言うと、学習する段階で、テストデータを一切知らせてはいけない!ということ

具体的に説明していくと、上の図のように訓練用データの中に、仮テストデータやテストデータが含まれてはいけないということです!
訓練データの中に、テストデータが含まれるということは、答えを知っている。
つまり、カンニングし放題の状態であるという事になります。
これは大問題ですよね!
もちろん、わざとLeakageをおこす人はいないですが、気づかないうちに、情報が漏洩している(=訓練データにテストデータが含まれる)場合があります。
よくある事例
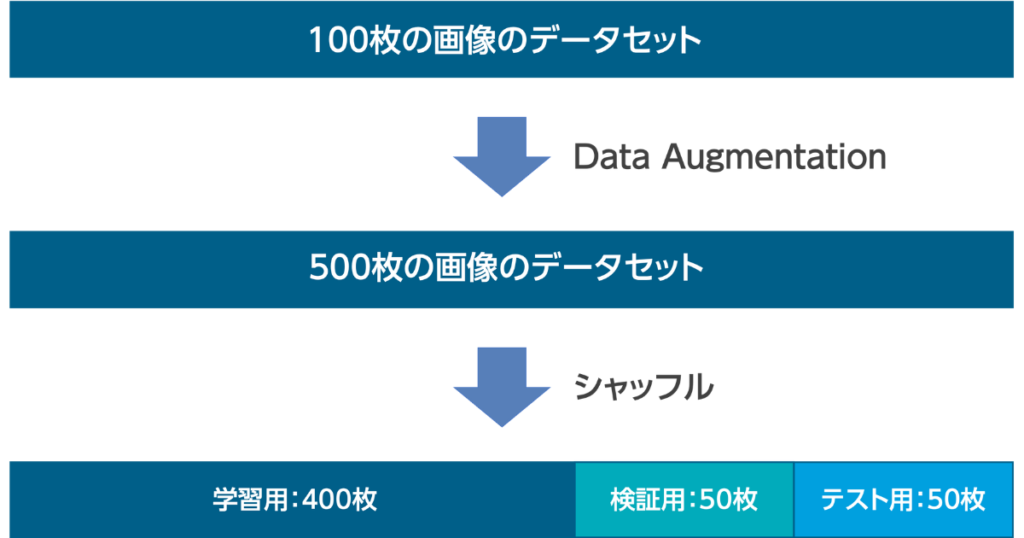
上の図のように、元画像100枚の画像に対して、回転、反転、ノイズなどのデータの水増し(Data Augmentation)を行うことにより、500枚に増やし、その後、シャッフルして訓練データ400枚、仮テストデータ50枚、テストデータ50枚にデータセットを分割しました。
データの水増しは、画像を増やしたと考えてください!
何が問題でしょうか?
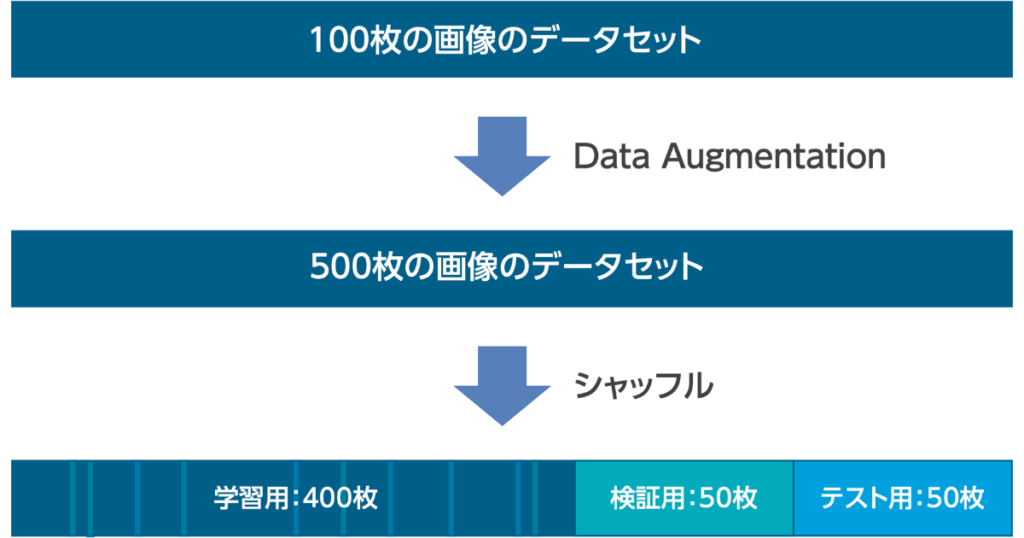
⇒訓練データにテストデータの一部が混入してしまう
これが問題ですね!1枚の画像から複数枚が生成されているので、画像全部を増やしてシャッフルしてから訓練用、仮テスト用、テスト用に分割してしまうと上の図からも分かるように訓練データの中に混入してしまう可能性があります。
改善するには
水増しするのは、訓練データのみにする!これが解決策であり、必ず守るようにしてください!
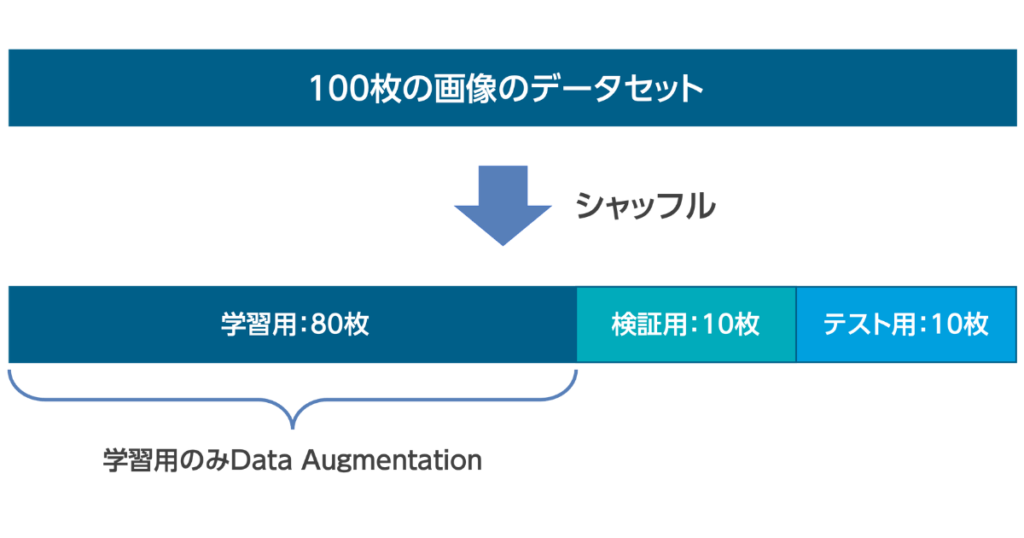
上の図のようにすることで、Leakageを防ぐことが出来ます。
Leakageの危険性
改めて、Leakageとは訓練データにテストデータの情報が混入してしまう事でしたよね。
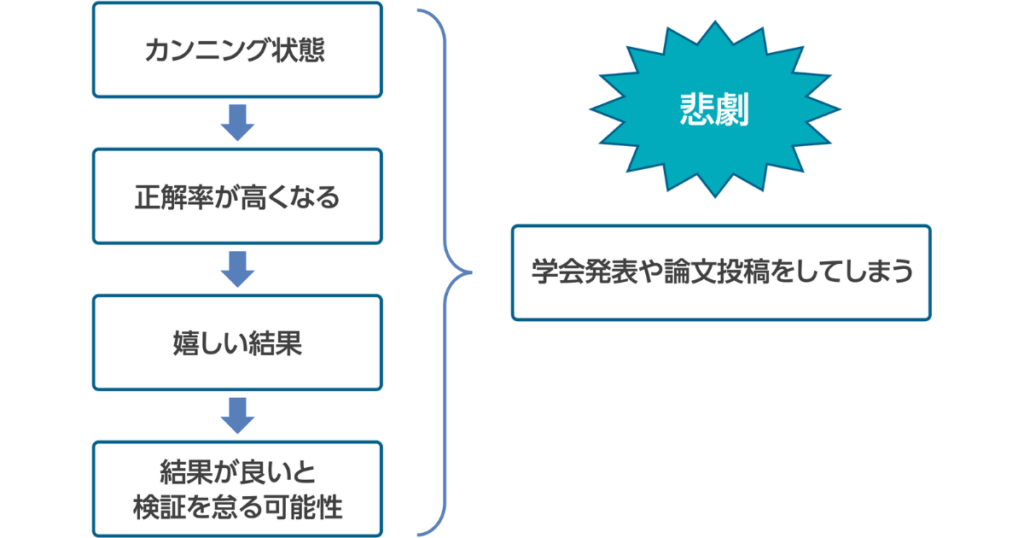
Leakageについてしっかりと理解していないと上図のように、悲惨な事にもなりかねないので気を付けてくださいね!
Leakgeについては、詳しくこの記事に書いてあるので、参考に見てみてくださいね!
▼ Leakageについて、まとめた記事はこちら

まとめ
今回の記事では、機械学習とは?これだけは押さえておくべき知識について解説しました!
参考にしてもらえると嬉しいです。
コメント