




【初心者向け】連合学習(Federated Learning)とは?わかりやすく解説

この記事では、Googleが2017年に提唱して以来大きな注目を集めている技術である連合学習(Federated Learning)について、わかりやすく解説したいと思います。
連合学習とは?
連合学習(Federated Learning)とは、学習データセットが分散している環境での機械学習モデルの汎用的な学習法の1つであり、データそのものを集めることなく、AIの学習によって得られたパラメータのみを統合する機械学習の方法です。
一般的に、機械学習において精度を上げるには多くのデータをモデルに学習させる必要があります。
連合学習と従来の機械学習との違い
連合学習と従来の機械学習の違いは「学習方法」にあります。
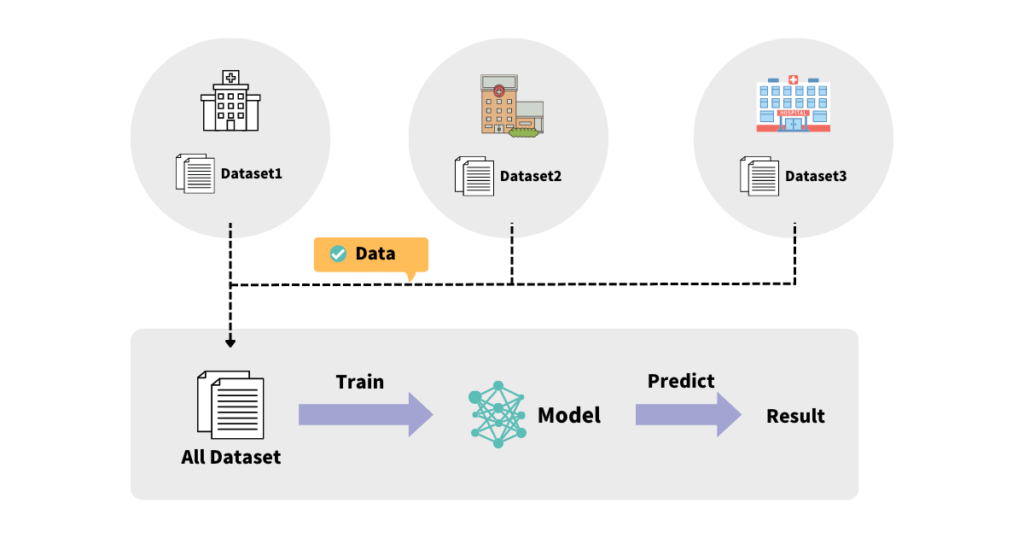
従来の機械学習では、下図のように学習用のデータを1つの大きなデータセットに集約し、それから機械学習モデル (例: 線形回帰モデル、ニューラルネットワーク) を学習するということを行ってきました。
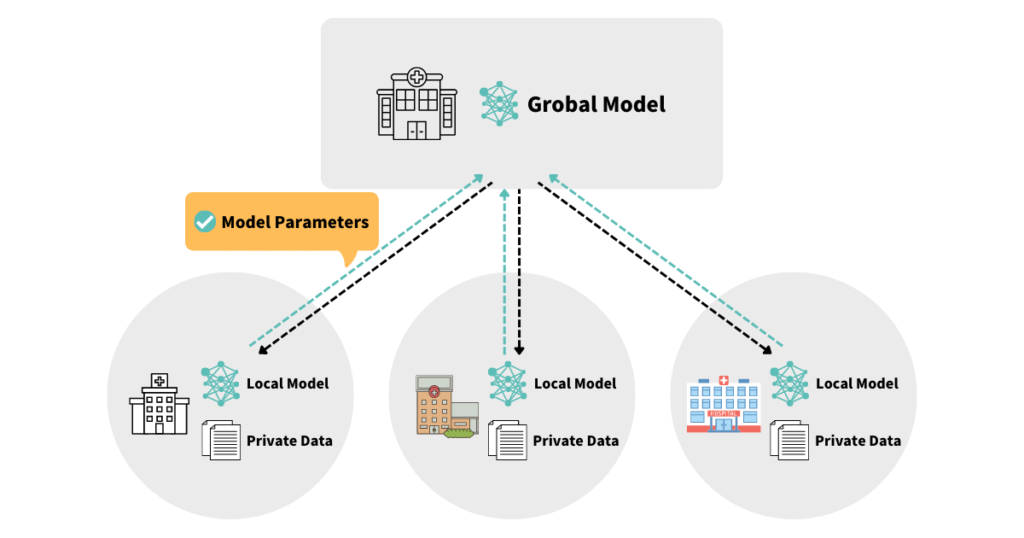
これに対して連合学習では、下図のように分散している学習データセットを分散させた環境のままモデルを学習させます。
学習場所が分散しているものの使用するモデルは同じであるため、得られるAIモデルは通常の1ヶ所で学習させたモデルと同じになります。
連合学習の具体的な学習の流れ
連合学習の具体的な学習の流れは、以下のとおりです。
- 共通のモデルを各々の環境(サーバ等)に用意する
- 各々の環境で解析を行い、ローカルモデルによるパラメータが生成される
- ローカルモデルのパラメータのみを中央の統合環境に送る
- 統合環境で各々の結果を統合し、総合的なグローバルモデルを生成する
- 統合環境から各々の環境に、グローバルモデルのパラメータが共有され、繰り返すことでアップデートする
これらの1~5の手順を繰り返すことで、徐々に高精度の解析結果やモデルが得られることになります。
連合学習のメリット
一般的に、機械学習やAIモデルの精度向上には、大量のデータによる学習が必要です。
一定程度のパフォーマンスを発揮するAIモデルを作る場合、大体1クラスにつき数千〜数万、数十万といったデータが必要であると言われています。
従来は、データを1ヶ所に集めて学習させていましたが、複数の会社や施設から学習データを提供される場合など個人情報等の厳重な取り扱いが必要な場合には、データを1ヶ所に集めることは現実的ではありません。
なぜなら、
クラウド等のデータ解析におけるセキュリティ対策が必要である。 機密性の高いデータの情報漏えい・改ざん等のリスク対策が必要である。
ためです。
その点、連合学習の場合はパラメータのみを統合するため、プライバシーやセキュリティに配慮した複数施設間でのデータ連携や、データ通信・保管を実現できます。
こうした特徴から、連合学習が注目されています。
連合学習のデメリット(課題)
連合学習は、プライバシーの問題に考慮して学習が出来るというメリットがある一方で、デメリットもあります。
いくつかの施設で、サーバーを介してモデルのパラメータを送ることで更新するため、各施設に学習を行えるだけではなく、サーバー通信などの知識を持った人がいる必要があります。
また、施設にAI学習に必要な環境の構築も必要であり、連合学習を行うだけの環境と人材が必要であるというデメリットがあります。
現実的には、大学や大企業などそれなりの人材や環境を持っている施設同士が連携することでしか連合学習は難しいため、連合学習の研究が加速するにはまだまだ課題も多いのが現状です。
連合学習の活用事例
連合学習の特徴として、プライバシーやセキュリティ面での強みがあります。
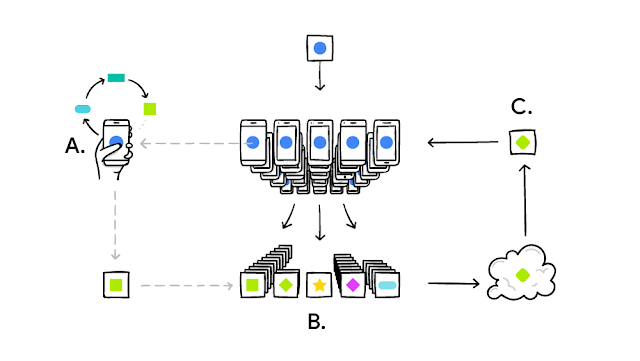
例えば、Googleは各スマートフォンユーザーの予測変換履歴から連合学習を用いて予測変換モデルを学習させています。
医療・ヘルスケア領域における連合学習の活用事例
Owkin
医療系AIスタートアップのOwkinは、連合学習の技術を用いて医療データのプラットフォームを運営しています。
Owkinでは、正しい治療の精度を向上させることを目的に、各医療機関が保有するカルテデータの機械学習に取り組んでいます。
また、乳がんおよび大腸がん向けAIソリューションが、欧州における規制当局の承認(CEマーク)を受けました。
さらに、Owkinは、米CB Insightsが例年公表する「世界の有望AIスタートアップ(AI 100)」の2022年版にも選出されています。
NVIDIA
NVIDIAは、「NVIDIA Clara Imaging」という医用画像処理における AIの開発と導入を加速するアプリケーションフレームワークを提供しており、連合学習の研究を様々な国で行っています。

さらに、NVIDIAは実際に20の医療機関のもつ胸部 X 線やバイタル情報、臨床検査値等を用いて COVID-19 に罹患した患者の酸素投与判断モデルを連合学習を用いて構築しています。

MELLODDY
創薬分野において、連合学習を用いた事例もいくつかあります。その代表例にはMELLODDYがあります。
ブロックチェーンと連合学習を組み込んだマルチタスク予測機械学習アルゴリズムを含むプラットフォームでコンソーシアムの集合的な知識を活用して、医薬品開発に最も効果的な化合物を特定すると同時に、知的財産権を保護することを目的としています。
参加企業には、ジョンソン・エンド・ジョンソン、アストラゼネカ、グラクソ・スミスクラインなどの製薬会社があります。
Elix
Elixは、「創薬を再考する」をミッションとしたAI創薬企業です。
連合学習(Federated learning)機能を有したAI創薬向け機械学習ライブラリkMoLをリリースしています。
kMoLは、データに含まれる化合物の機密性を外に出すことなく、大量のデータから創薬の生成につながるデータを提供できると期待されています。

NEC
2022年3月、NECが秘密計算と連合学習を組み合わせ、創薬における予測モデル構築の実証実験を行いました。
同実証実験は、連合学習技術を基盤として手を加えた機械学習ライブラリにNECの秘密計算技術を適用して実施し、様々な化合物と毒性が記載されているデータセットを用いた毒性予測モデル等を評価しました。
この実証実験の結果は、連合学習モデルに秘密計算技術を適用して構築したAIモデルは、連合学習技術のみで構築したAIモデルと比較して同等の精度を満たすことを確認しました。
連合学習の将来の可能性
エッジコンピューティングへの応用
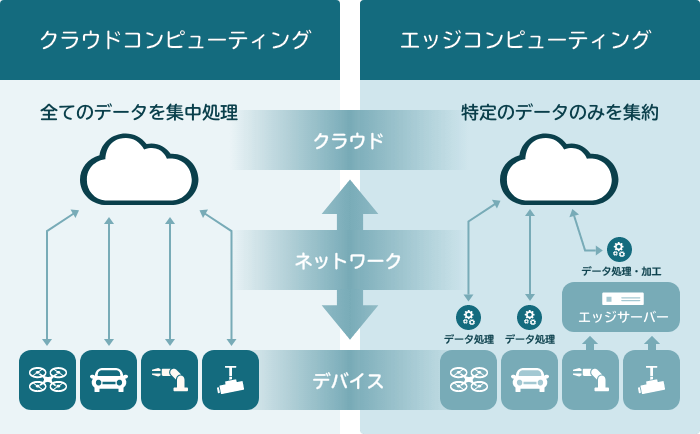
クラウド上の1ヶ所にデータを集約して処理するクラウドコンピューティングに対し、ユーザーに近いデバイス等やデバイスと物理的に近い場所に分析処理機能を持たせることから、エッジ(末端)コンピューティングと呼ばれています。
不要な通信を避けることで通信遅延やネットワーク負荷の低減などを実現します。
さらに必要なデータ・解析結果のみをクラウドに送ることで、ユーザーの属性や個別性の高い情報をクラウド上に送る必要がなくなり、セキュリティも担保されます。
ブロックチェーン×AIの親和性
連合学習には、前に紹介したような「中央集権型の学習モデル」もありますが、中央の統合環境を無くす完全な分散型(P2P)への取り組みも期待されています。
完全な分散型の場合、SPOF(単一障害点)がなくなり、障害に対して強靭なシステムになります。
また、管理にブロックチェーンを用いることでもモデル改ざんのリスク対策となります。
このように、連合学習およびAIとブロックチェーンを連携した応用例も検討がはじまっています。
医療データを用いるには、やはり個人情報の壁は大きな課題であり、ブロックチェーンとの相性も良く、今後の可能性を秘めた分野だと言えます。
まとめ
この記事では、連合学習(Federated Learning)について、わかりやすく解説しました。
連合学習の特徴からメリット・デメリット、そして将来性まで解説しました。
注目されている技術であり、ブロックチェーン・医療分野とも相性の良い技術なので、ぜひこの機会に連合学習について学ぶ参考にしていただけたら嬉しいです。
コメント