




医療AIのトレンド・最新技術まとめ8選【2020年代最新版】

今回の記事では、2020年代の最新技術やホットなテーマについてまとめていきたいと思います。
AIは、日々とてつもないスピードで進化しています。
最新の技術やトレンドを把握しておく事は、医療AIの発展において非常に重要です。
この記事を読むことで、「医療AIのトレンドの概要」を理解することが出来ます。
Vision Transformer(ViT)
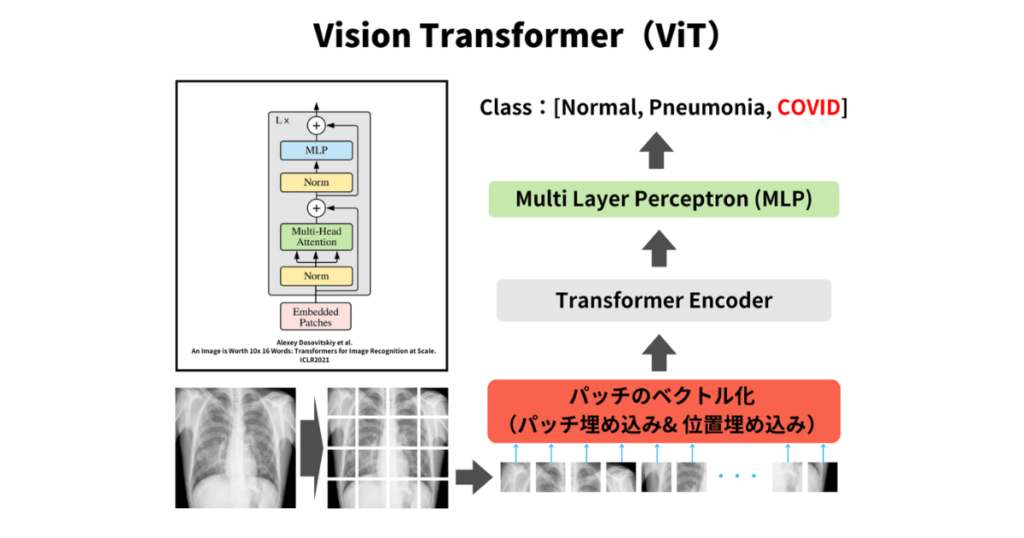
Vision Transformerとは
Vision Transformer(ViT)は、コンピュータビジョンのタスクにおいて、従来の畳み込みニューラルネットワーク(CNN)に代わる新しいアーキテクチャとして登場した、Transformerベースのニューラルネットワークです。
Transformerは、元々自然言語処理(NLP)の分野で発表され、大きな成功を収めました。その後、Transformerを画像認識や物体検出などのコンピュータビジョンタスクに適用する研究が行われ、Vision Transformerが開発されました。
Vision Transformerは、従来の畳み込みニューラルネットワーク(CNN)よりも高い精度を発揮することができるとされており、注目されています。
Vision Transformerの特徴としては、以下の4つがあります。
- CNNよりも高精度
- パッチの位置関係を考慮できる
- テクスチャよりも形状に注目しやすい
- 学習データが膨大に必要
Vision TransformerとCNNを組み合わせたハイブリットなモデルなども登場しています。
医療AIにおいても、Vision Transformerを活用することで、病理学的画像診断や画像診断を支援するための高度なモデルの開発が進んでいます。
医療AIにおけるVision Transformerの応用事例
- ViTによるマンモグラフィ分類

- ViTによるSegmentation、Detectionへの応用
- 3D、時系列への応用
Self-supervised Learning(自己教師あり学習)
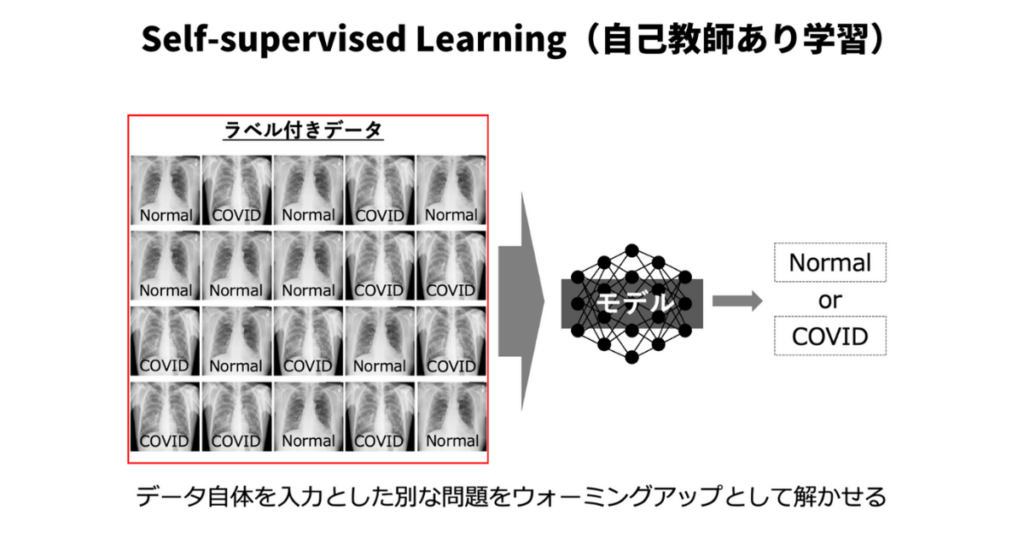
Self-supervised Learningとは
自己教師あり学習(Self-supervised Learning)とは、ラベル付けされていないデータから知識や特徴を学習するアプローチです。自己教師あり学習では、教師あり学習(Supervised Learning)とは異なり、ラベルやアノテーションが必要ありません。代わりに、データそのものやデータ間の構造、関係性を利用して様々なタスクを解決します。
実際に解きたい問題とは別に、入力データを教師とするような問題を解くことで、ウォーミングアップとして特徴を学習できるとされています。
具体的には以下のような3つの方法を紹介します。
- Auto encoder
- Contrastive Learning
- GAN
一つ一つ説明していきます。
Auto encoder
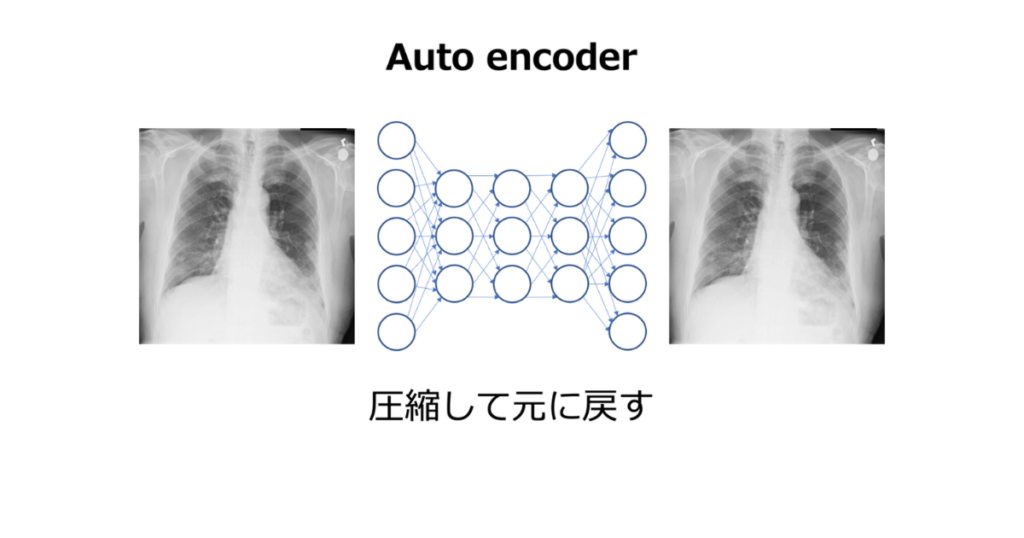
入力データを低次元の表現にエンコードし、その低次元のデータから元の入力データを再構築(デコード)することを学習します。このプロセスで、モデルはデータの重要な特徴を抽出し、圧縮された表現を学習します。
Contrasitive Learning
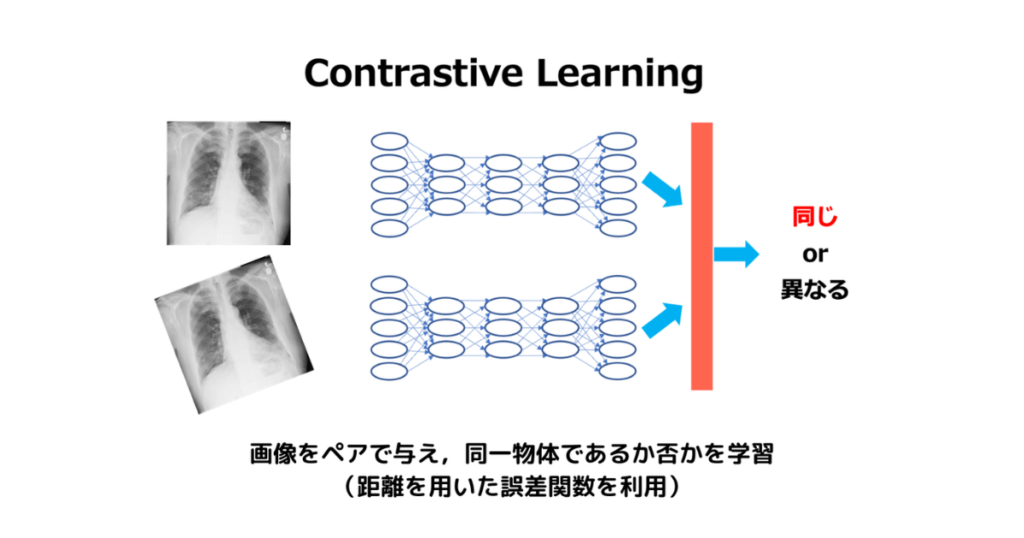
似たようなデータサンプルが近く、異なるデータサンプルが遠くなるような表現空間を学習します。これにより、モデルはデータの構造やパターンを理解することができます。
GAN
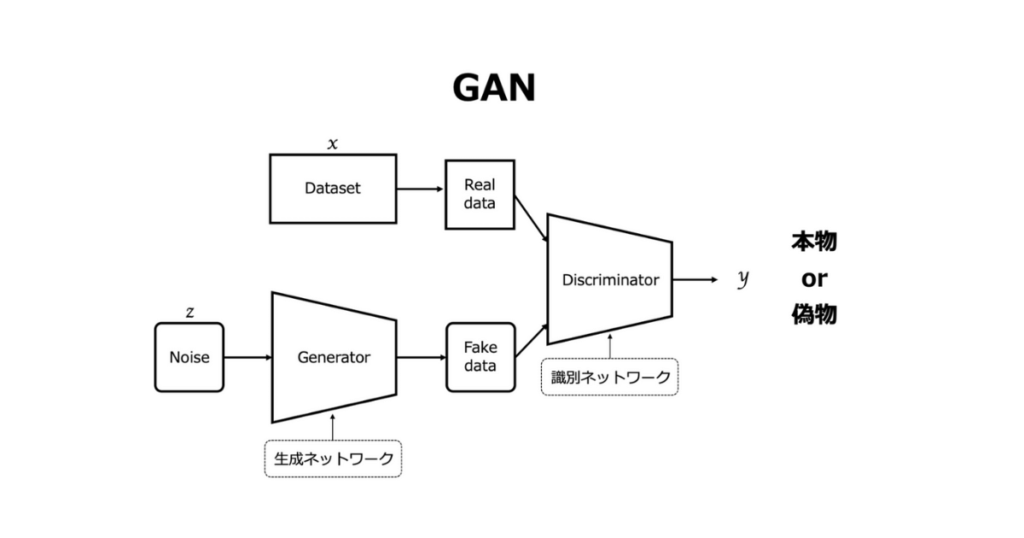
生成器と識別器という2つのネットワークが競合するように設計されたモデルです。生成器はデータを生成し、識別器はそれが本物か偽物かを判断します。この相互作用を通じて、生成器はより本物に近いデータを生成し、識別器はより正確に判断することを学習します。
また、自己教師あり学習は、異なるタスク間の共通性を学習することができるため、マルチモーダル学習などの応用にも活用されています。
医療AIにおけるSelf-supervised Learningの応用事例
- ルービックキューブ
- ランダムマスク

- 脳波解析
Semi-supervised Learning(半教師あり学習)
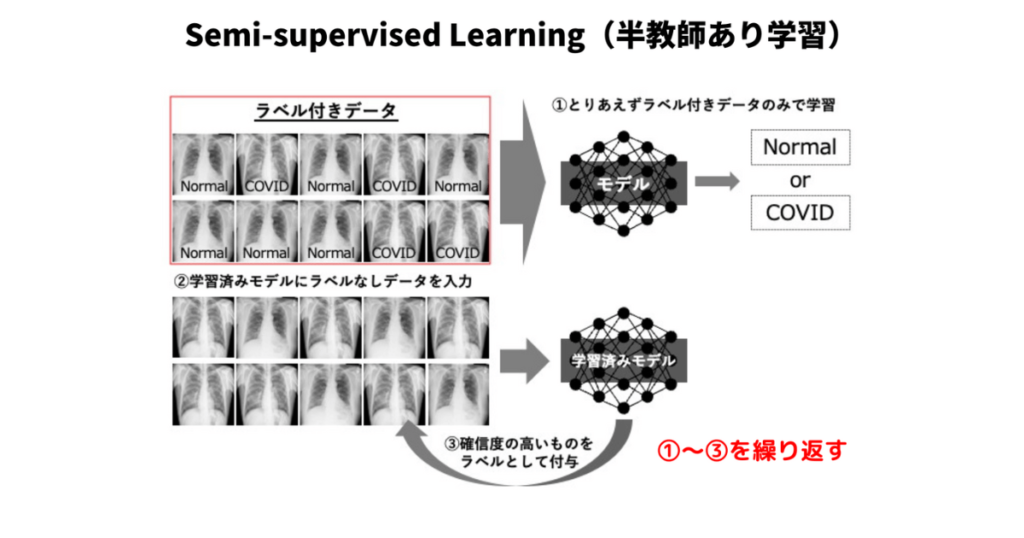
Semi-supervised Learningとは
半教師あり学習(Semi-supervised Learning)とは、少量のラベル付きデータと大量の未ラベル付きデータを組み合わせて学習を行うアプローチです。半教師あり学習は、教師あり学習(Supervised Learning)と教師なし学習(Unsupervised Learning)の中間に位置し、両者の利点を活用しています。
教師あり学習では、ラベル付きデータを利用してモデルが特定のタスク(分類や回帰など)を学習します。しかし、ラベル付きデータの取得にはコストや時間がかかることが多く、実際の問題では十分な量のラベル付きデータが利用できない場合があります。一方、教師なし学習では、ラベルなしのデータからパターンや構造を学習することができますが、特定のタスクに対する性能が低い場合があります。
半教師あり学習では、少量のラベル付きデータを利用してタスクに関する基本的な知識を学習し、未ラベル付きデータを用いてその知識を拡張し、モデルの性能を向上させることを目指しています。このアプローチは、データのラベル付けコストを削減しながら、高い性能を達成する可能性があります。
一般的な方法としては、モデルが未ラベル付きデータに対して予測を行い、その予測結果を新たなラベルとして使用してモデルを再学習させる方法があります。これを繰り返すことで、より良い学習を行うことが出来ます。
医療AIにおけるSemi-supervised Learningの応用事例
Active Learning(能動学習)
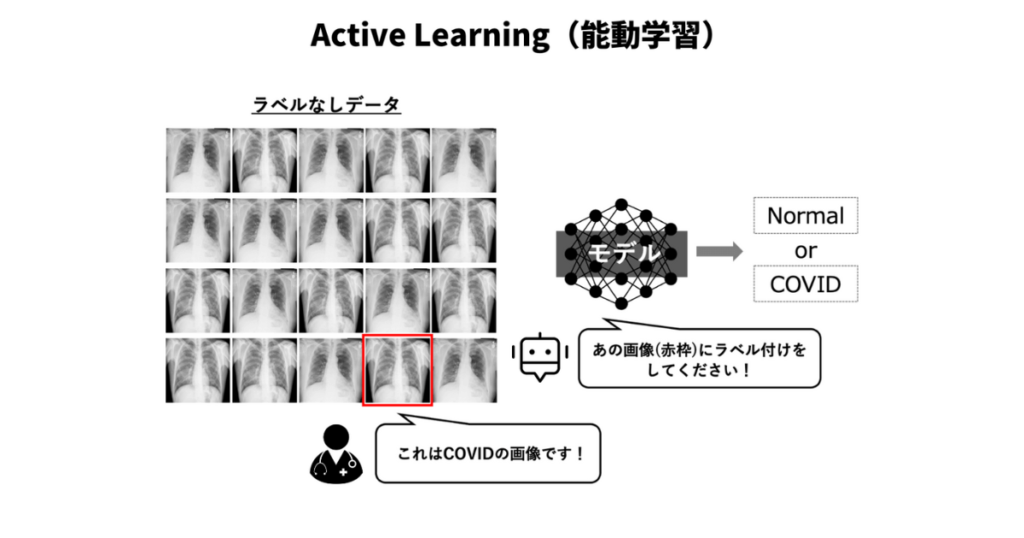
Active Learningとは
能動学習(Active Learning)とは、学習アルゴリズムが能動的にデータのラベル付けをリクエストすることで、学習効率を向上させるアプローチです。従来の教師あり学習では、ラベル付きデータが事前に与えられることが前提となりますが、能動学習では、モデルが自身でどのデータがラベル付けされるべきかを判断し、必要なデータのみをラベル付けすることで、効率的な学習を行います。
能動学習は、特にラベル付けコストが高い場合や、ラベル付けに専門知識が必要な場合に有効です。
一般的な方法としては、モデルが最も不確かなデータを選び、そのラベルをリクエストします。不確かさは、分類器の出力における確率分布のエントロピーによって評価されます。
医療AIにおけるActive Learningの応用事例

Weakly-supervised Learning(弱教師あり学習)
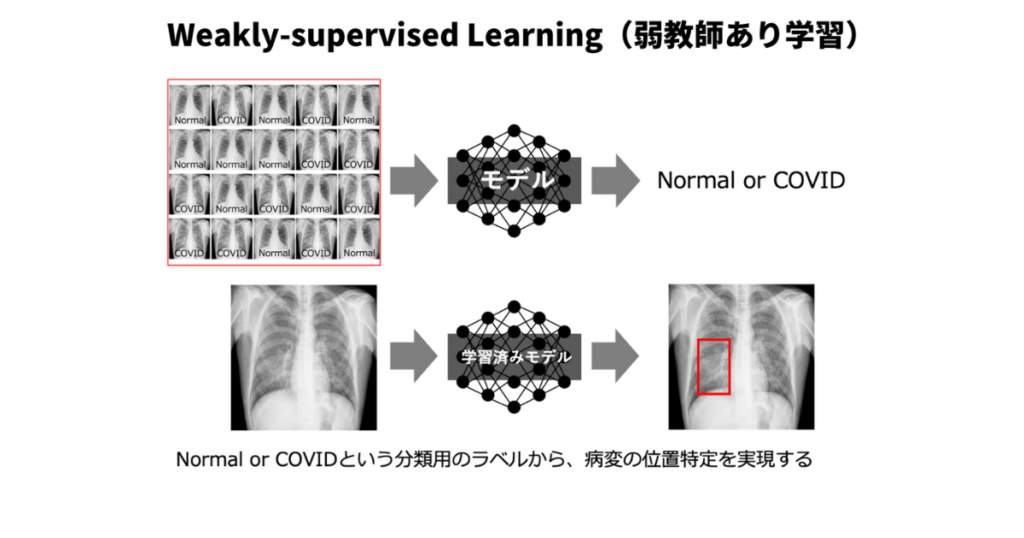
Weakly-supervised Learningとは
弱教師あり学習(Weakly-supervised Learning)とは、不完全 or 不正確である、または間接的な教師情報(ラベル)を用いてモデルを学習させるアプローチです。完全な教師情報が利用できない状況や、ラベル付けコストが高い状況で効果的に利用されます。弱教師あり学習は、教師あり学習と教師なし学習の間に位置し、半教師あり学習や能動学習といった他の学習アプローチとも関連があります。
例えば、物体検出のタスクをする際に、画像中で検出したい物体を矩形(Bounding Box)で囲ったデータではなく、検出したい物体が写っているか否かの分類タスクに用いる様なラベルが付いているデータを使用するイメージです。
矩形を囲う作業(アノテーション)は、画像ごとに存在するか否かのラベルを付ける作業と比べて、時間的にも費用的にもコストが高いので、このような手法が有効であるとされています。
医療AIにおけるWeakly-supervised Learningの応用事例
- 糖尿病性網膜症
Multi-task Learning(マルチタスク学習)
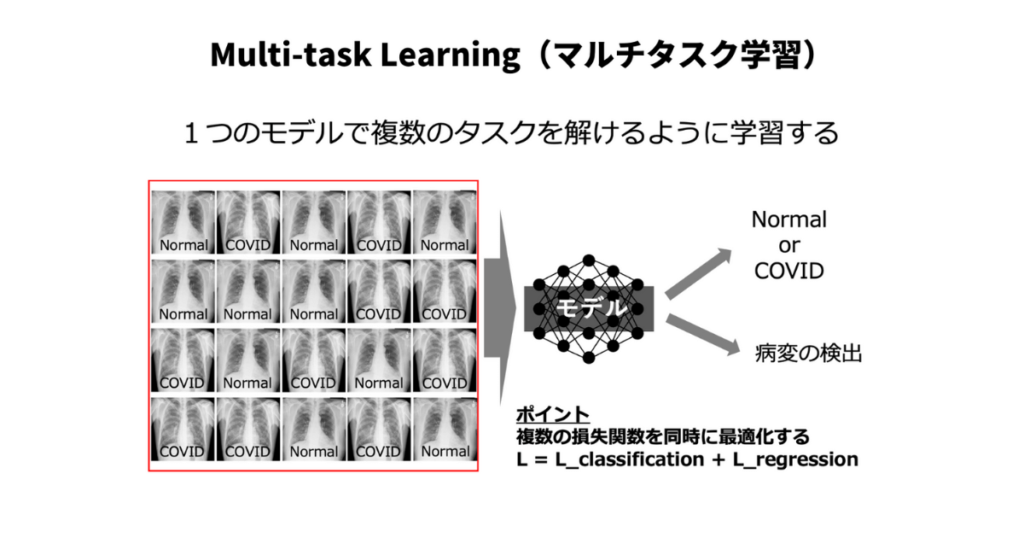
Multi-task Learningとは
マルチタスク学習(Multi-task Learning)とは、複数の関連するタスクを同時に学習することで、モデルの性能を向上させるアプローチです。マルチタスク学習では、複数のタスク間で知識や特徴量を共有し、モデルがそれぞれのタスクに対する共通の表現を学習することを目指します。この共通の表現が、モデルの一般化能力を向上させ、個別にタスクを学習する場合よりも高い性能を達成することが期待されます。
マルチタスク学習の主な利点は以下の通りです。
- データ効率の向上:複数のタスク間で知識を共有することで、各タスクのデータ利用効率が向上し、全体的に高い性能を達成することができます。
- 一般化能力の向上:共通の表現を学習することで、モデルの一般化能力が向上し、未知のデータに対しても適応しやすくなります。
- 転移学習(Transfer Learning):あるタスクで学習した知識を別の関連するタスクに転移させることが可能です。これにより、データが少ないタスクでも高い性能を達成することができます。
- 訓練時間の短縮:複数のタスクを同時に学習することで、個別にタスクを学習する場合よりも訓練時間を短縮することができます。
医療AIにおけるMulti-task Learningの応用事例
- 肺結節の検出

- 乳癌分類
Multi-modal Learning(マルチモーダル学習)
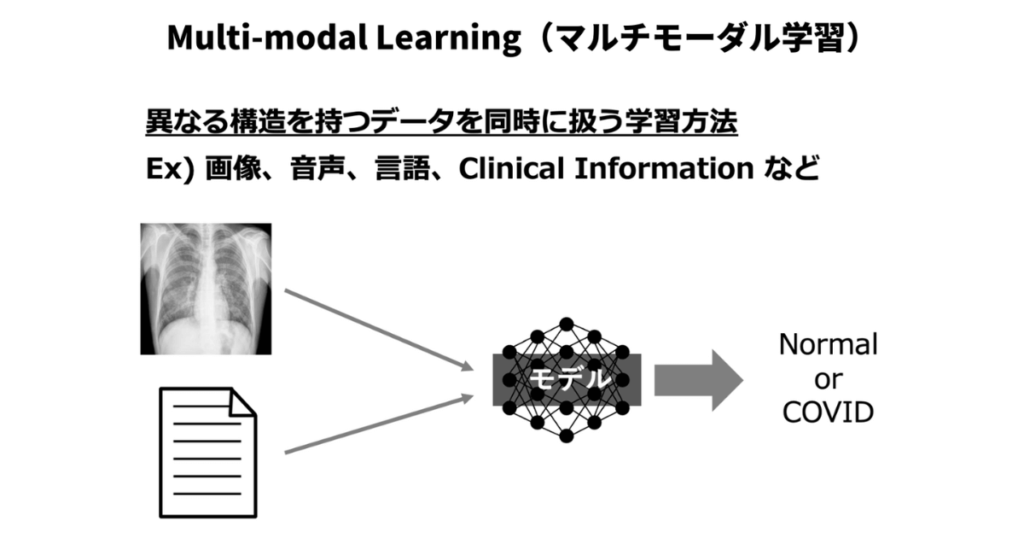
Multi-modal Learningとは
マルチモーダル学習(Multi-modal Learning)とは、異なる種類のデータ(モダリティ)から共同で学習し、情報を統合することを目的としたアプローチです。これにより、異なるデータソース間の相補的な情報を活用して、タスクの性能を向上させることができます。マルチモーダル学習は、自然言語処理(NLP)、コンピュータビジョン(CV)、音声認識など、さまざまな研究分野で活用されています。
一般的なマルチモーダル学習のタスクには、以下のようなものがあります。
- 画像キャプション:画像を入力として受け取り、その画像の内容を説明するテキストを生成します。
- 動画解析:動画や音声データを組み合わせて、その内容を理解し、アクションを認識するなどのタスクを行います。
- テキストと画像のタスク:画像とテキストを組み合わせて、質問応答や図表の理解などのタスクを行います。
- 音声とテキストのタスク:音声データとテキストデータを組み合わせて、音声認識や音声合成などのタスクを行います。
マルチモーダル学習の主な利点は以下の通りです。
- 異なるデータソース間の相補的な情報を活用:それぞれのモダリティが持つ情報を統合することで、より豊かな表現が得られ、タスクの性能が向上します。
- ロバスト性の向上:複数のモダリティを使用することで、一部のデータが欠落していても、他のデータを用いてタスクを実行できます。
- より現実的な問題解決:現実世界の問題は、通常、複数のデータソースから情報を取得する必要があります。マルチモーダル学習は、これらの問題に対処するための効果的な手法を提供します。
医療AIにおけるMulti-modal Learningの応用事例
- 電子カルテ、CT/PET

Diffusion Model(拡散モデル)
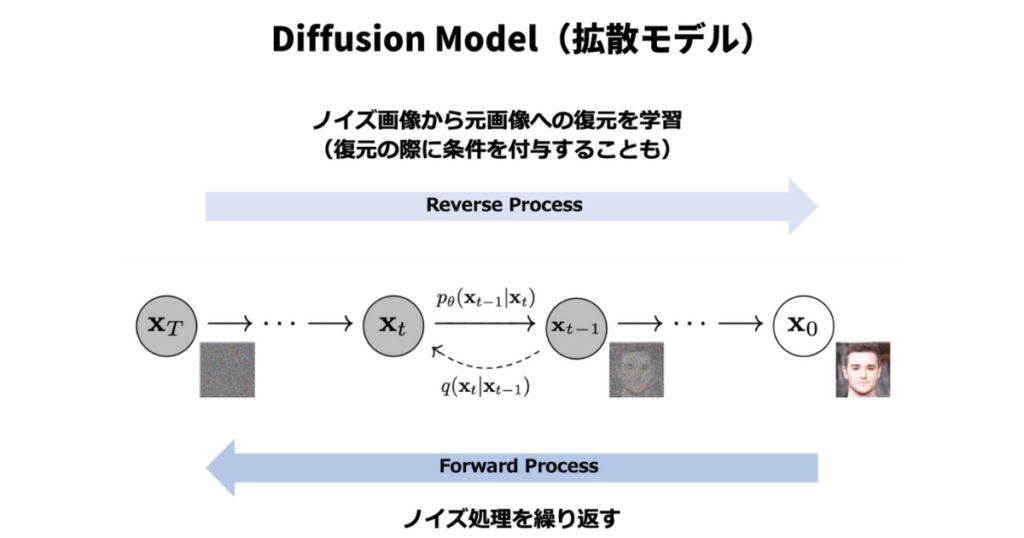
Diffusion Modelとは
拡散モデル(Diffusion Model)とは、確率的な過程を用いてデータ生成やデータ復元を行う手法であり、機械学習や画像生成の分野で研究されています。拡散モデルは、通常、ノイズの追加や除去に関する確率的なプロセスを表す拡散方程式に基づいています。
最近の研究では、拡散モデルは、生成モデルとしてディープラーニングのアーキテクチャ(例:ニューラルネットワーク)と組み合わせて用いられています。拡散モデルは、データを生成するために、ノイズからスタートし、徐々にノイズを除去していくことで、データを生成するモデルです
拡散モデルは、画像生成や自然言語処理などの分野で利用されており、生成モデルとしての性能が高いことが示されています。例えば、高品質の画像生成やテキスト生成が可能であることが報告されています。
医療AIにおけるDiffusion Modelの応用事例
- 胸部X線
- MRI 脳腫瘍
- 拡散モデルを用いた異常検知
おわりに(まとめ)
今回の記事では、医療AIのトレンド最新技術8選を紹介しました。
医療AIは、医師の負担軽減やワークフローの効率化と改善に役立つ可能性を持っています。
しかし、日本は医療AI先進国に比べて5年以上も遅れています。医療AI機器として承認を受けている数も約20程度であり今後更なる発展が必要とされています。
日本の医療データ(画像)は、非常に質が高く有効活用できれば日本の医療AIの発展も加速する可能性があります。
今後は、今回紹介したような最新技術を組み合わせた研究・開発が重要となります。
今回のまとめ記事が、そのためのきっかけとなると嬉しいです。
コメント